���ڱ��������Ϣ���뿴����ٷ���վ��http://restfulwebservices.cn/
ǰ��
���ӵ�ϵͳ�����ɼ�ϵͳ�ݱ�����ġ�
��John Gall
Systemantics
����д�Ȿ�飬��Ҫ������һ��������Ŀ���¼����������������ţ����᳹�ı����DZ�д�ֲ�ʽϵͳ�ķ�ʽ������Ҫ��������ά����World Wide Web�����Web����
û����Web����ʲô�¼�����Ҳ����������ô���ˣ����ҴӼ����Ƕ�����������������ô������Ŀ��������ȷ�ı����������ࡣ��10������Web�Ѿ��ı�����������ķ�ʽ������������DZ�ڵĸı佫�ȴ����ǡ�Web�Ǽġ��������ڵģ�Ȼ��������Ϊ�ֲ�ʽ���ƽ̨��DZ��ȴ�������ˡ����DZ�д�����Ŀ�ģ�����Ҫ�ô������Web������DZ����
˵Web��Ϊ�ֲ�ʽ���ƽ̨��DZ���������ˣ�������ȥҲ�����˸е����졣�Ͼ������黹Ҫ������Web��������鼮�����������ǣ������� ��Web������Web����ϵ�����Dz�����COM��CORBA�������������ֲ�ʽ������ʼܹ���������Web�ļ��Ա������ۡ����ġ�Web���� �ܹ��ظ��������Web���Գɹ���ÿһ�����ԡ�
��ʵ������Ҫ������Web����ģ�underlying����������֧��ǿ���Զ�̷�����ʵ��Щ����ʹ����ţ���������ÿ�춼��ʹ�����ǡ����ַ���������쵽��Ĺ�ģ������ʵ���Ѿ�ʵ���ˡ���Google��������Ϊ������������һ���Ժ������ݿ���в�ѯ�����ؽṹ�����������Զ�̷�����ͨ�������Dz�����վ��web site������������service������������Ϊ��վ�������û����ˣ��������dz���֮��ĶԻ�������վ���Ƿ���
ÿ��WebӦ�ã�����ÿ����վ������һ������service����ֻҪ���Web�����������Υ������ֻҪ����Web���е����������ںܶ�����֮�£�����ܹ��ÿɱ��Ӧ�ã�programmable applications�����������������������á�Web���ع顰Web�������ʱ���ˡ�
����վ���ڱ�������ʹ�õ���Щ���ԣ�ͬ��Ҳ��Web����API���ڱ�����Ա��ʹ�á�ΪѰ�ҷ�������ԭ�����ǿ��Դ���վ�����ԭ�����֣���˼�������վ��ʹ���߲����˶��dz��������ս��õ�ʲô�������ԭ��
���������ô���ġ����ǵ�����Ŀ�꣬����չʾWeb����������HTTPӦ��Э�顢URL��������XML������ԣ���ǿ�����������ó��ϼ����ȡ�������Ҫ������Web����ģ�underlying��һ�����ԭ����ʾ��״̬ת�ƣ�Representational State Transfer��������ΪREST����������Ϊ��RESTʽ��RESTful����Web������������ʵ����best practices�������Dz�����ú������ܶ��Ե����ԣ��෴�����þ���Ľ�����ȡ����Щ���䴫�ԣ�folklore��������֪ʶ��
����������������Դ�ļܹ���Resource-Oriented Architecture��ROA����Ϊ�������RESTʽWeb����RESTful web services����һ���к�ʵ�ʵ�ԭ�����ǻ��������α�д�ͻ��˳���������RESTʽ�������ǽ�����һЩ��ʵ��RESTʽ������Ϊ���������磺 Amazon S3��Simple Storage Service��������Atom����Э��ı��Σ��Լ�Google Maps�ȡ�����Ҳ���һЩ���еĵ�������RESTԭ������ӣ����� del.icio.us ���������ǩAPI����Ȼ������ǽ����ع���
���ڱ��������Ϣ���뿴����ٷ���վ��http://restfulwebservices.cn/
��Web
Ϊ�����Ƕ�Web������ԣ���������Ϊ���ܽ���������⣿Ҳ�������ϵ��ˣ���Ϊ�������ܺ��ߡ�����HTTP���������ܻ�ӭ�� InternetЭ�飬��Web�����DZ�����������һ��Internet��������ͳ�ƣ�ȫ��Internet�����еĴ�Դ�Ե����ʼ��������������ʼ�����BitTorrent���������ַ���Ȩ������������Internet�Ͳ������ڣ���ô������Ϊ����Ľ��ǵ����ʼ�����Ϊ��Ҫ�������Web�أ���ʲôʹ��HTTP����һ��Ϊ����ʵ����֮�䴫���о���¼����Ƶ�Э�顪��ͬʱ�ܹ��ʺϷֲ�ʽInternetӦ���أ�
ʵ���ϣ�˵HTTP��ΪijijĿ�Ķ���Ƶģ�������һ�ּ���Ĺ�ά���Ѿ�����˵�ˣ�HTTP��HTML�ǡ�InternetЭ����ķ�ƨ���棨Whoopee Cushion���뻶�ַ�������Joy Buzzer����ֻ�ܸ�ЩС��Ϸ������ע1���������һ��ϲ�����ǵ���˵�ġ���ע1����һ��HTTP����HTTP 0.9����ȷ����ȥ���Ǹ�С��Ϸ��������������ͻ�������������������ӣ�
�ͻ������� ��������Ӧ
GET /hello.txt Hello, world!
����ô�������ӵ������������ĵ�·��������Ȼ��������Ͱ��ĵ����ݷ��ظ��㡣HTTP 0.9 ����ֻ֧����ôЩ�ˣ�����ֻ�Ǻ�����ɫ���հ��������һ����ļ�����Э�飨FTP����
����������ǣ��𰸻����������������ǿ��뿪��Ц�ؽ���HTTP���ر��ʺϷֲ�ʽInternetӦ�õģ���Ϊ��û��ֵ��һ������ԡ��㽲Ҫʲô������ʲô��������Ƭ����ַ�ͬ��һ�ޣ���ע2��HTTP��ȱ��ת���������ƣ����ļ���ת������ǿ��������
HTTP 0.9���ص���Ƴ���ô�ġ���HTTP 0.9�����ǿ��Կ�����Ѱַ�ԣ�addressability������״̬�ԣ�statelessness�����������������������ԭ����HTTP����ͬ��������㣬���������쵽������˾�Ĺ�ģ����HTTP 0.9��ȱ�ٵ������У����ѱ�֤ʵ�Ƕ���ģ��������и����õģ���ʵ��������Щ���Խ�������Web�����������������������HTTP 1.0��1.1����ʵ���ˡ�Web���Գɹ�����������Ҫ������URL��HTML���Լ�������XML������������������Ҫ����Ҳ�Ǽġ�
��Ȼ����Щ���ġ������ڹ��������㹻ǿ������֧��Web��Web�ϵ�Ӧ�á��ڱ����У����ǽ�һ���������ά����World Wide Web����һ�������ķֲ�ʽ��̻���������������Ϊ��ԭ���ǣ�Ϊ����ʹ�ö���Ƶ�human web����Ϊ����������ö���Ƶġ�programmable web��û�б�������������Ϊ�����Web�ܺܺõ�Ϊ�������ã���ô��Ҳͬ���ܺܺõ�Ϊ�������á�����ֻҪ����һЩ���Ǽ��ɡ�����������ó��ڹ����ͽ������ӵ����ݽṹ�������������ĵ����棬����������������һ����
���ڱ��������Ϣ���뿴����ٷ���վ��http://restfulwebservices.cn/
���ӵĴ�Web����
��������Web�����Э������кܶ࣬���Ǵ���ǹ�����HTTP֮�ϵġ���Щ����ͳ��ΪWS-*��ջ�����ǰ���WS- Notification��WS-Security��WSDL��SOAP�ȡ��ڱ����У������á���Web����Big Web Services�������ƺ���Щ�������Խ�Ϊ��ò�ر������Ƕ����ı��ӡ�
���鲻����Щ������ϸ���ܡ����Ǿ��ã�ʵ��Web����һ���ǵ��ô�Web����Big Web Services�����෴����Web���㹻�ˡ��������ţ�Web�����������Գ�ΪĬ�ϵķֲ�ʽ����ƽ̨��
����ijЩWS-*��������SOAP�������������ʹ�����ǣ�����Υ��REST��������Դ�ļܹ���Resource-Oriented Architecture������ʵ���ϣ����DZ�����ʵ�ֻ���HTTP��Զ�̹��̵��ã�Remote Procedure Call��RPC������ʱ������RPCʽ�ܹ��Ǻ��ʵģ���ʱ���б�Web���ŵ��Ϊ��Ҫ������ÿ��ǡ���û��ϵ��
����Ҫ�ĸ��������������������ġ���Щ���ϣ�������ͨ��ʽ��HTTP��plain old HTTP��������Ӧ���ˣ�������Ա��˾ȴ�������ô�Web����Big Web Services������������Ч���ǣ�HTTP��Ϊһ�����ڴ����Ӵ�XML���أ�payload����Э�飬���������ġ�������Ϣ��XML����յķ�����̫�����ӡ����ڵ��ԣ�����Ҫ��ͻ��˱��������˾߱�ͬ�������û�����
��Web����Big Web Services��ȷʵ�и��ŵ㣺�ֽ�Ŀ�������ʹ��ֻ���һ����꣬�Ϳ��Ը��ݴ�������Web����������Java��C#��������������Щ���������ɷ���WS-*��ջ��RPCʽWeb����ʱ��RESTʽWeb����ļ�����һ�ŵ������˵Ҳ���Ѿ�����Ҫ�ˣ���Ϊ��Щ�����Ѿ����������еĸ����ԣ�����������ġ��Ͼ�������CPU�����ˡ�
��������ͬ�ʣ�homogeneous�������У��ҷ�����ͬһ������ǽ֮��Ļ�����ô���������ǿ��еġ������Ļ������㹻������Ӱ����������Ҫ�����ǽ�����������Ҳ���ø�����ͬ���ķ�ʽ�����ǣ���������������չ��Internet��ģ���ͱ����ܹ�Ӧ��û�����ȿ��ǵ��Ŀͻ��ˣ�����������û�뵽���Զ�������ջ��software stacks�������ʷ����û�����ͼ����ķ�����������û��˵���ķ���������ò�ƺ��ѣ�����Web���Ѿ�˾�ռ����ˡ�
����abstraction��Ҳ���������ġ�ÿ����һ����Σ��Ͷ�һЩ���ϵ㣨failure point��������������Ϳ����������⡣�ִ������������ܹ����ظ����ԣ���������Ϊ���븴���Խ���ԭ�����Ǿ�֪�����ϵ����Ӳ�Ρ�Ҫ��������� Web����Ҫ����Ӧ�ԣ�adaptability�����������ԣ�scalability������ά���ԣ�maintainability��������ע�⡣�����ԣ�simplicity������HTTP 0.9�����ӵ��ŵ㡪�����������ߵ��Ⱦ�������ϵͳԽ���ӣ�����ʱ����������Խ���ѡ�
������ṩRESTʽWeb�����Ѹ�����Ͷ�롰ʵ�ָ������ԡ�ʵ�ֲ�ͬ����֮��Ľ������С��ɹ����ṩ������ζ�Ų���ѷ�������Web ��֮�ϡ�������Ӧ�����������Web����Ʒ���ʱ��Ӧ��ѭ�������õ���վ��������õġ�һ����ԭ��������WebЭ�鿿��Խ£�����Խ����ʵ�֡�
����REST
REST��Ȼ�����������ö���ģ�well-defined�������ң�������Ϊ��Web�������վ��һ���Ķ����������Լ�����Ϊ���� Web����ʵ�ֳɹ���ƶ������վ���Ľ�ڡ���ϧ��ĿǰΪֹ����Ҫ��REST�ο�����ֻ��Roy Fielding 2000��IJ�ʿ���ĵ�5�¡����Ͳ�ʿ������˵�����Ǻܺõ����ϣ��������ڴ���ʵ���⣬����û�и����ش𡣣�ע3��������Ϊ����ƪ��ʿ���IJ��ǰ� REST��Ϊһ�ּܹ���ڹ�ͣ����ǰ�REST����һ�����мܹ��ķ��������ܵġ���RESTʽ��RESTful���������������������object- oriented�����������һ����һ�����ԡ�һ�ֿ�ܻ�һ��Ӧ��Ҳ���Dz����������ķ�����Ƶģ����Ⲣ��һ��ȷ����ܹ����������ļܹ�����ע3��
��ʹ������C++��Ruby��������������ԣ�Ҳ�п���д�����������������ij������������REST�ı���HTTP���������Ǻܺõġ�������������Ȼ�ģ���ΪFielding������HTTP���ı�д���������ڲ�ʿ������������Web�ļܹ���������������ʵ�У���վ��WebӦ�ü�Web����Ⱦ�����RESTԭ����Υ������ô���ڶԾ����Web����������ʱ������������ȷ���Լ���ȷ������RESTԭ���أ�
�ֹ���REST����Ϣ��Դ���Ƿ���ʽ�ģ��ʼ��б���mailing list����Wiki�����͵ȣ����ڸ�¼A�и�����һЩ�ܺõ����ӣ���ֱ�����REST�����ʵ����best practices����ֻ��һЩ���䴫�ԣ�folklore��������Ҫ�ģ���һ����RESTԪ�ܹ���meta-architecture��Ϊ�����ľ���ܹ���architecture����һ��Ϊ��ơ�������Web��DZ�����ķ�����ƶ��Ļ��������ǽ��ڵ�4�½�������һ�ּܹ�����������Դ�ļܹ���Resource-Oriented Architecture�����ROA������������Ψһ�ĸ߲㣨high-level��RESTʽ�ܹ�������������Ϊ����������ơ�����Ϊ�ͻ������á��� Web�����Ǻܺõġ�
����ͨ���ƶ����������Դ�ļܹ���ROA���������Է��䴫�ԣ�folklore���ľ�������ΪWeb������Ƶ����ʵ����best practices�������ǽ���Ϊһ������Ļ��ߣ�suggested baseline���������������ͼ���REST��ϣ�����ǵļܹ��ܹ��������ŵ���Ϊ�������ǡ������ġ�REST������Ҳϣ����������Դ�ļܹ���ROA���ܹ��������������ӿ������ϵͳ�����ʵ������ϣ���ó���Ա�������ع������ŵġ����������;�ġ�����Web�ģ������ǽ���������Web֮�ϵģ��ֲ�ʽ WebӦ�á�
������֪�������������Щ�������Dz����ġ��������˶����й������ľ������������Ļ���������Ҫ�ļܹ�������û�а������ǵ���˼ȥ�������û������� RESTʽ�ܹ�����������RESTʽ�ܹ�����ȡ�óɹ��ġ���Ϊ�����˼���֪ʶ���⣬���ǻ���������������Դ�ȥ�Ƽ�RESTʽ��������������Ѿ���������Դ�ļܹ���ROA����λΪһ�����RPCʽ�ܹ���������SOAP+WSDL���������õģ��ļ�����RPCʽ�ܹ�ͨ��һ�����ӵġ��������ʽ�Ľӿڣ�����¶���ڲ��㷨��algorithms���������ֽӿڣ�ÿ����������ͬ����ROA��ͨ��һ���ġ��ĵ������ӿڣ�����¶���ڲ����ݣ�data���������ֽӿ���ͳһ�ġ����ǽ��ڵ�10�¶������ּܹ����ԱȽϣ�������������Ƽ�����ROA��
���ڱ��������Ϣ���뿴����ٷ���վ��http://restfulwebservices.cn/
ͳһ����Web
����Ա����վ��ΪWeb�������ã����Ѿ��кö����ˡ�����Ȼ���Ƿ���ʽ�ġ���ע4��Ҫ�ü������������Ķ�����ҳ���DZȽ����ѵģ����Ⲣû����ֹ������������Զ����ͻ�����ץȡ��ҳ��Ȼ������Ļץȡ��������ȡ�й���Ϣ������ʱ����ƽ���������RSS��XML-RPC��SOAP��Щ�Գ���Ա�Ѻõļ��������������ڰ���ʽ�Ͽɵķ�ʽ����¶��վ���ܡ���Щ�����γ���һ��programmable web�����Ƕ�human web����չ����Ϊ���������ṩ�˷��㡣
����д�Ȿ�������Ŀ�ģ���ͳһprogrammable web��human web������������ǵ������������磺һ������һ������������У�����һ��Э�鲢���һ�����ԭ����ά����World Wide Web��������һ���ȿɱ���Ҳ�ɱ����������ʹ�õ����硣
�����ǵ����ڷ��䲻���Ĺ����ʽ𡢴��µĹ�����Ŀ�����������á���worse-is-better���Ĺ���ʵ�������ѧ������������������塢�Źֵ������������Ρ��������ţ��Լ���Щ��Ϊ�Լ��ҵ��˷���֮·�ij���Ա��Ͷ���ߵĺ�ˮ���ʱ�����������Internet������ά����World Wide Web��Ҳ����һ���ᵮ����
Web��Ϊһ���ġ����ŵģ������ֽΣ��ͻ���ͳһ������Ӧ��ƽ̨���������˴���������֪ʶ����Ϊ������Ŭ�����е����������ṩ֧�֡�������Ϊ������Ӧ�ÿ�ʼ���濼�ǽ���վ���ԭ��Ӧ���ڷ�����ƣ��Ա��Զ����ͻ��˿��Է�����Щ��Ϣ���㷨������ͬ��Ļ������齫������ô����
���ڱ��������Ϣ���뿴����ٷ���վ��http://restfulwebservices.cn/
���������
�ڱ����У�������Ҫ��עһЩʵ�����⣺��������ʵ��RESTʽWeb����RESTful Web Services�����Լ��������ǵĿͻ��ˡ�������ǻ���ע�����۷��棺ʲô��RESTʽ�ܹ����ΪʲôWeb����Ӧ�þ�������REST������ǵ����۲��ậ�Ƿ������棬������ͼ���������ص㻰�⡣��Ϊ����ͬ�����еĵ�һ�������ǻ�Ϸ�����һ�ؼ����⡪����������һ��RESTʽ����
ǰ3�£����ӿͻ��˵ĽǶ�������Web����������RESTʽ������ʲô�ر�ͬ����1�� Programmable Web�������
��������һ�¶�Web�����������Խ��ܡ�Web����������Web�ϣ������ⲿ�������ṩ���ݻ������㷨�ij������ǽ�չʾ���ֳ�����Web����ܹ��� RESTʽ�ܹ���RPCʽ�ܹ���REST-RPC��ϼܹ������ǻ�Ϊÿһ�ּܹ���һ��HTTP����/��Ӧ�����ӣ����������͵Ŀͻ��˴��롣
��2�� ��дWeb����ͻ���
����һ�£����ǽ��������HTTP���XML��������Ϊ����Web�����д�ͻ��ˡ����ǽ�����һ�����е�REST-RPC���� del.icio.us Web������Ruby��Python��Java��C#��PHP��������ʾ����ͻ��˴��롣��������һЩ���ԣ�������Ȼû��չʾ���룬�����Ƽ�һЩ���õ�HTTP���XML��������JavaScript��Ajax���ڵ�11�������������ܡ�
��3�� RESTʽ������ʲô�ر�ͬ��
���ǽ���ȡ��2�µľ��飬������Щ����������һ����RESTʽ����Amazon S3��Simple Storage Service�������ǽ��ڹ���S3�ͻ���ʱ����˵��һЩ��Ҫ��REST�����Դ��resource������ʾ��representation����ͳһ�ӿڣ�uniform interface����
����6���DZ���ĺ��ģ����ǹ�ע�������ƺ�ʵ���Լ���RESTʽ����
��4�� ������Դ�ļܹ�
������ʽ����REST�����dz���ؽ��ܣ�������һ�������Web����ܹ�Ϊ�������н��ܡ����ǵļܹ������ĸ���Ҫ��REST�����Դ����Դ���ơ���Դ��ʾ��representation�����Լ���Դ������ӡ����ķ���Ӧ�����ĸ�REST���������У���Ѱַ�ԡ���״̬�ԡ���ͨ�Ժ�ͳһ�ӿڡ�
��5�� ���ֻ����������Դ�ķ���
��������ˡ����뷨������ת��ΪRESTʽ��Դ����ϵ�в��衣��Щ��Դ��ֻ���ģ�Ҳ����˵�ͻ��˿��Դӷ����ȡ���ݣ����Dz��ܸı��������ݡ�������һ����Ƶ�ͼ��������Google Maps����������˵����Щ���衣
��6�� ��ƿɶ�д��������Դ�ķ���
������չ����һ�µIJ��裬�������ͻ��˴������IJ�ɾ����Դ��������Ϊ��ͼ��������������Դ���û��˻����Զ���ص㣩Ϊ����ʾ����Щ���衣
��7�� һ������ʵ��
���ǰ�һ��RPCʽ������2���Ǹ�del.icio.us REST-RPC��Ϸ����ع�Ϊһ����RESTʽ����Ȼ�����ǰ��������ʵ��Ϊһ��Ruby on RailsӦ�á�ͨ����һ�£��������ѧ����֪ʶ����һ�飡
��8�� REST��ROA���ʵ��
����һ�£����ǰ�֮ǰ�����Ĺ��ڷ�����ƵĽ���㼯������������һЩ�µĽ��顣���ǽ��������������HTTP�ı������������������ͽ����Ż������ǻ���Ϊ���ֵ����ԣ���������Ҳ������Ϊ��û����RESTʽWeb������ʵ�֣�����������Դ����ơ�
��9�� ����ļ�������
��������һ��������REST����������HTTP��URI��XML��֮�ϵ�������������Щ�����ڴ���״̬���ĵ���ʽ������XHTML������ʽ��microformat������Щ������Ϊ�ͻ���״̬�ƽ��ij�ý���ʽ������WADL����Щ�����ڹ���RESTʽWeb����Ŀ�����������Atom����Э�顣
���3���漰һЩר�Ż��⣬��Щר����Զ��ɵ�����Ϊһ���������ۡ�
��10�� ������Դ�ļܹ� VS ��Web����
�������ǵļܹ���һ���REST�ܹ������������ܹ������бȽϡ�������ΪRESTʽWeb����ϡ�����SOAP��WSDL��WS-*���ķ�����ԣ���Ϊ���������Ը��á�������ʹ�á����ӷ���Web������Ҹ���Ӧ�����ָ����Ŀͻ��ˡ�
��11�� ��AjaxӦ����ΪREST�ͻ���
����һ�£����ǽ���Web��������������WebӦ�õ�Ajax�ܹ���һ��AjaxӦ�ã�����һ��������������е�Web����ͻ��ˡ������ǶԵ�2�����ݵ����졣���ǽ��������XMLHttpRequest�ͱ���JavaScript������д����RESTʽWeb����Ŀͻ��ˡ�
��12�� RESTʽ������
�������һ������ǽ������������еĿ�ܣ�Ruby on Rails��Restlet������Java����Django������Python�������ǿ��Լ�RESTʽWeb����Ŀ�����
���ǻ���3����¼��ϣ���������á�
��¼A REST�����Դ��RESTʽ��Դ
��һ�����г���һЩ��RESTʽWeb�����йصı����̳̺��������ڶ����ָ�����һЩ���еġ������ġ��ɹ�����ú�ѧϰ��RESTʽWeb����
��¼B 42�ֳ�����HTTP��Ӧ����
�ⲿ�ֽ��ͱ�HTTP��ÿһ����Ӧ���루�Լ�һ����չ���������ͺ�ʱ�����RESTʽWeb�������õ���Щ���롣
��¼C ������HTTP��ͷ
�ⲿ�����������HTTP��ͷ������ÿ������HTTP��ͷ���Լ�һЩ����Web�������չ��ͷ��
���ڱ��������Ϣ���뿴����ٷ���վ��http://restfulwebservices.cn/
��Ӧ���Ķ���Щ���֣�
�������֯��������Щ��Web����ĸſ�����Ȥ�Ķ��ߣ���Щ����ͨ��ʵ��ѧϰWeb�������Ƕ���Web����û��̫�ྭ�顣���������������������Բ�ȡһ������Ķ�·�ߣ����ӱ��鿪ͷһֱ������9�£�Ȼ����ʣ�µ��½���ѡ����������Ȥ�IJ��֡�
����㾭��ȽϷḻ����ô���Բ�ȡ��һ���Ķ�·�ߡ������������Ϊ���з����д�ͻ��ˣ���ô����ֻ��ע��1��2��3��11�¡�����Щ���ڷ�����Ƶ��½ڶ�����ܰ��������������Ҫ�����Լ���Web��������֪��REST������ʲô��˼���㲻���ӵ�3�¿�ʼ�Ķ����������Ƚ�REST��WS- *����ô�����ѡ��1��3��4��10����Ϊ��㡣
˵��
��������λ���ߣ�Leonard��Sam�����ڱ����1-11�£����ǽ������������ݺϲ�Ϊ��һ�˳ơ��ҡ����������һ�£���12�£�������һ�˳ơ��ҡ���������һ��Ⱥ�ˣ���Ϊ���ڶ�Django��Restlet�������Dz��뵽��չʾ��������ǵĿ��������RESTʽ����������
���Ǽٶ�����һ��ʤ�εij���Ա�������ٶ�����Web��̷������κξ��顣���������н��ܵ����ݲ�������ijһ������ԡ������ṩ���Ը������Ա�д��RESTʽ�ͻ��˼������ʾ�����롣����Ϊ��ʾ���ض��Ŀ�ܻ����ԣ��������ǽ�����Ruby��http://www.ruby-lang.org��������������
����ѡ��Ruby����Ϊ����ʹ���ڲ���Ruby�ij���Ա��˵����Ҳ�Ǽ�����ġ�����Ϊ����һ�źܺõ����ԣ������������ָ�Sam�������������������ϵ����Ruby�ı�Web��ܡ���Ruby on Rails����Ҳ������Ҫ��һ��RESTʽWeb����ʵ��ƽ̨֮һ������㲻��RubyҲû��ϵ�������ڴ�����Ƕ������������������Ruby���ע�͡�
�����ʾ��������Դӱ���ٷ���վ��[URL=http://www.oreilly.com/catalog/9780596529260]http://www.oreilly.com/catalog/9780596529260[/URL]�������أ����а�����7�µ�RailsӦ�õ��������룬�Լ���12����Restlet��DjangoӦ�õ���Ӧ���롣�����У�����ͻ�������ֻ������ Rubyʵ�֣�����ʾ�������У��㻹�����ҵ����ǵ�Javaʵ�֡���Щ�ͻ��˳��������Restlet�⣬��������Restlet������Jerome Louvel��Dave Pawson��д�ġ������Ruby���ԣ������ϤJava����ô��Щ����������մ��뱳��ĸ�����а������ر�ֵ��ע����ǣ�ʾ�������ﻹ����һ�������ĵ�3��Amazon S3�ͻ��˵�Javaʵ�֡�
���ڱ��������Ϣ���뿴����ٷ���վ��http://restfulwebservices.cn/
��л
�������Ҫ��л��Щ�����ǵ���ֱ����HTTP�ϱ�̵����ǡ�����Sam��˵����Rael Dornfest������Blosxom����Ӧ�á�Leonard�ľ���������20����90������ڱ�д��ĻץȡӦ�á�����л��Щ����վ��ΪWeb��������Ƶ����ǣ��ر�����λ������������Pokey the Penguin�����������ߡ�
�������й��������뷨��������Roy Fielding��ʵ�������������ǣ���ֻ��һ�ָо�����Roy Fielding�������IJ�ʿ����������������������Roy�����ۻ�����������������Ϊ�����ġ�
�ڱ����д�����У����Ǵ�REST��������˾�İ��������Ƿdz��м������Ƿ������ˣ�Benjamin Carlyle��David Gourley��Joe Gregorio��Marc Hadley��Chuck Hinson��Pete Lacey��Larry Liberto��Benjamin Pollack��Aron Roberts��Richard Walker��Yohei Yamamoto������һЩ��ͨ�����ǵ���Ʒ�ڲ�֪�����а������ǣ�Mark Baker��Tim Berners-Lee��Alex Bunardzic��Duncan Cragg��David Heinemeier Hansson��Ian Hickson��Mark Nottingham��Koranteng Ofosu-Amaah��Uche Ogbuji��Mark Pilgrim��Paul Prescod��Clay Shirky��Brian Totty��Jon Udell����Ȼ�����е����п��������ܴ��ڵĴ�������©���������Լ������Ρ�
�ڱ����д�����У��༭Michael LoukidesΪ�����ṩ�˺ܶ�������ǻۡ����ǻ�Ҫ��лLaurel Ruma����������Ϊ������渶���Ͷ���O��Reillyͬ���ǡ�
�����Ҫ�ر��л����Jerome Louvel��Dave Pawson��Jacob Kaplan-Moss��������Restlet��Django����ľ������������˱���ĵ�12�¡�
���ڱ��������Ϣ���뿴����ٷ���վ��http://restfulwebservices.cn/
[�������Ѿ���������2008-5-16 19:32:37�༭��]

 [����] ����XML��̳ - רҵ��XML���������� ��
W3CHINA.ORG������ - Web�¼������� �� �� Web Services & Semantic Web Services �� �� ��RESTful Web Services ���İ桷���� ���� ��ǰ�ԡ�
[����] ����XML��̳ - רҵ��XML���������� ��
W3CHINA.ORG������ - Web�¼������� �� �� Web Services & Semantic Web Services �� �� ��RESTful Web Services ���İ桷���� ���� ��ǰ�ԡ�



 (���ı���)
(���ı���)








 ������
������










 ��RESTful Web Services ���İ桷���� ���� ��ǰ�ԡ�
��RESTful Web Services ���İ桷���� ���� ��ǰ�ԡ�
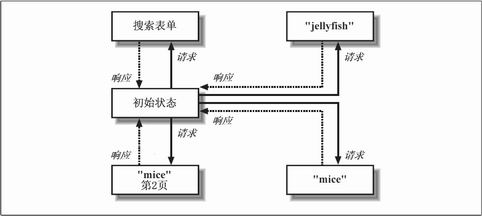
 ���������ͼƬ���£�
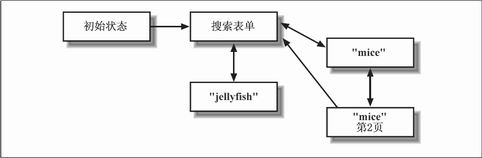
���������ͼƬ���£�